
Authors:
(1) Albert Gu, Machine Learning Department, Carnegie Mellon University with Equal contribution ([email protected]);
(2) Tri Dao, Department of Computer Science, Princeton University with Equal contribution ([email protected]).
Table of Links
3 Selective State Space Models and 3.1 Motivation: Selection as a Means of Compression
3.2 Improving SSMs with Selection
3.3 Efficient Implementation of Selective SSMs
3.4 A Simplifed SSM Architecture
3.5 Properties of Selection Mechanisms
4 Empirical Evaluation and 4.1 Synthetic Tasks
4.4 Audio Modeling and Generation
4.5 Speed and Memory Benchmarks
6 Conclusion, Acknowledgments and References
A Discussion: Selection Mechanism
B Related Work and B.1 S4 Variants and Derivatives
B.4 Linear Attention and B.5 Long Context Models
D Hardware-aware Algorithm For Selective SSMs
E Experimental Details and Additional Results and E.1 Synthetic Tasks
3 Selective State Space Models
We motivate our selection mechanism using intuition from synthetic tasks (Section 3.1), then explain how to incorporate this mechanism into state space models (Section 3.2). The resulting time-varying SSMs cannot use convolutions, presenting a technical challenge of how to compute them efficiently. We overcome this with a hardware-aware algorithm that exploits the memory hierarchy on modern hardware (Section 3.3). We then describe a simple SSM architecture without attention or even MLP blocks (Section 3.4). Finally, we discuss some additional properties of selection mechanisms (Section 3.5).
3.1 Motivation: Selection as a Means of Compression
We argue that a fundamental problem of sequence modeling is compressing context into a smaller state. In fact, we can view the tradeoffs of popular sequence models from this point of view. For example, attention is both effective and inefficient because it explicitly does not compress context at all. This can be seen from the fact that autoregressive inference requires explicitly storing the entire context (i.e. the KV cache), which directly causes the slow linear-time inference and quadratic-time training of Transformers. On the other hand, recurrent models are efficient because they have a finite state, implying constant-time inference and linear-time training. However, their effectiveness is limited by how well this state has compressed the context.
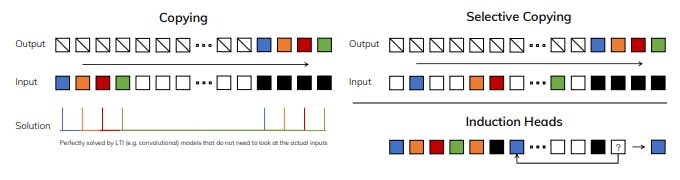
To understand this principle, we focus on two running examples of synthetic tasks (Figure 2).
• The Selective Copying task modifies the popular Copying task (Arjovsky, Shah, and Bengio 2016) by varying the position of the tokens to memorize. It requires content-aware reasoning to be able to memorize the relevant tokens (colored) and filter out the irrelevant ones (white).
• The Induction Heads task is a well-known mechanism hypothesized to explain the majority of in-context learning abilities of LLMs (Olsson et al. 2022). It requires context-aware reasoning to know when to produce the correct output in the appropriate context (black).

In summary, the efficiency vs. effectiveness tradeoff of sequence models is characterized by how well they compress their state: efficient models must have a small state, while effective models must have a state that contains all necessary information from the context. In turn, we propose that a fundamental principle for building sequence models is selectivity: or the context-aware ability to focus on or filter out inputs into a sequential state. In particular, a selection mechanism controls how information propagates or interacts along the sequence dimension (see Section 3.5 for more discussion).
3.2 Improving SSMs with Selection
One method of incorporating a selection mechanism into models is by letting their parameters that affect interactions along the sequence (e.g. the recurrent dynamics of an RNN or the convolution kernel of a CNN) be input-dependent.

This paper is available on arxiv under CC BY 4.0 DEED license.